
James Amoo, Community Partner
Feb 12, 2025

In today’s data-driven world, valuable data is the foundation for generating actionable insights, making informed decisions, and establishing a data-driven culture. However, not all data retains its value over time. As businesses grow and scale, managing data quality becomes increasingly complex, potentially accumulating stale data.
Stale data refers to outdated or contextually irrelevant information. While it may seem like a minor inconvenience, it poses a serious threat to decision-making, leading to what experts call data decay. If left unaddressed, stale data can undermine the accuracy of insights, reduce operational efficiency, and negatively impact business outcomes. In fact, research shows that organizations lose an estimated $13 million annually due to poor data quality, including stale data.
Eliminating stale data is not just about preventing data decay, it’s about achieving the full potential of your data. By prioritizing data freshness, organizations can enhance decision-making and generate important insights.
In this blog post, we’ll explore how to identify stale data, its underlying causes, and practical solutions to ensure your data remains accurate and relevant.
What is stale data?
Stale data refers to information that is outdated or no longer relevant to an organization. The relevance of data depends on its use case—while some data remains useful for months or years, others, such as real-time analytics, can become stale in just minutes.
Imagine you're booking a ticket on a ticketing platform. The website displays “3 tickets left”, but when you attempt to purchase, you receive an error: “No tickets available.” This happens when the system relies on data that hasn’t been updated in real time, leading to a frustrating customer experience simply because the data is stale.
Now, consider a more critical scenario. In a healthcare system, a doctor might prescribe the wrong medication based on outdated information if a patient's records are not updated in time. In such cases, stale data isn't just inconvenient—it can be life-threatening.
For organizations looking to extract meaningful insights and maintain a competitive edge, ensuring data freshness is crucial. To achieve this, strategic measures must be put in place to keep data up-to-date and relevant at all times.
What are the causes of stale data?
Understanding the root causes of stale data is the first step to preventing data decay. Let's explore the various factors that contribute to stale data:
- Delay in data collection: One of the main causes of stale data is delays in data collection, often due to outdated collection methods. In systems that require real-time updates, relying on manual processes like copy-and-paste or batch processing can result in stale data. For example, the case we discussed earlier of stale data in a ticketing platform was caused by delays in data collection.
- Data pipeline issues: Stale data can result from bottlenecks in the data pipeline, disrupting the ETL (Extract, Transform, Load) or ELT process. Since the ETL pipeline transfers data from source systems to target systems, any unnoticed or persistent failures can cause stale data to accumulate in the target system.
- Lack of data governance: Data governance refers to a set of internal standards and policies that outline data management processes throughout the data analytics lifecycle. Without structured policies, data quality can deteriorate over time, leading to data decay.
- Lack of real-time synchronization: Real-time synchronization of data ensures that data is uniformly updated across all the sources. Otherwise, discrepancies can arise, resulting in stale data. Organizations using multiple tools and platforms must ensure seamless data communication to maintain accuracy.
How to identify stale data
Now that we've explored stale data and its causes, the next step is to know how you can identify it. Let's explore the various methods for detecting stale data in our system:
- Evaluate timestamps: Each data entry includes a timestamp indicating when it was ingested into the system. Analyzing these timestamps helps to determine data freshness—outdated timestamps signal that data may be stale as it hasn’t been updated in a while. For instance, using last year's product prices to assess current inflation may lead to inaccurate conclusions.
- Audit your data pipelines: Perform regular evaluation of your data pipeline to ensure an optimized data delivery process.
- Set up monitoring systems: Manually reviewing large datasets for stale data can be time-consuming. Implementing a monitoring system automates the process, allowing you to easily identify old data. These systems can be configured to trigger alerts, instantly notifying you of anomalies in the data ingestion process.
- AI-powered spreadsheets: AI-powered spreadsheets like Quadratic simplify the process of identifying stale data. By simply entering text prompts, you can leverage built-in AI features to quickly detect stale data within your datasets.
What are the consequences of stale data?
We’ve established that freshness of data is crucial for generating actionable insights. Naturally, stale data hinders data accuracy, but its impact goes beyond that. Let’s explore the negative effects stale data can have on businesses:
- Wrong business decisions: In data-driven organizations, stale data results in poor decision-making, as stakeholders rely on outdated information that no longer reflects the current reality of the business. This can lead to financial losses and a weakened competitive advantage.
- Poor customer experience: When businesses rely on outdated data, they struggle to accurately understand customer needs and preferences, leading to a poor customer experience. For example, a recommendation platform using stale data may generate irrelevant suggestions, further reducing customer satisfaction.
- Loss of competitive advantage: To remain competitive and highly operational, businesses must work with fresh data. Outdated data can result in missed opportunities and weaken their competitive edge.
- Security and compliance risk: Stale data can lead to non-compliance with regulatory requirements, particularly in industries like finance and healthcare. Failure to meet these standards may result in financial penalties, legal consequences, and reputational damage.
- Reduced operational efficiency: Stale data reduces efficiency by causing delays and increasing the risk of errors, particularly in organizations that depend on timely and accurate data for daily operations.
How can stale data be prevented?
Preventing stale data requires a proactive approach to ensuring data freshness. Let’s discuss some prevention and mitigation strategies:
- Data monitoring and alerts: Implementing monitoring systems allows for continuous tracking of data metrics such as age and quality, helping to maintain data freshness. Automated alerts can be configured to trigger when unexpected changes occur, so administrators can take immediate actions even before data gets stale.
- Frequent data refresh: The frequency of data refresh varies by industry—some require real-time updates, while others may refresh data weekly. Regardless of the interval, implementing a timely data refresh policy is crucial for maintaining data freshness.
- Real-time data synchronization: As mentioned earlier, data can become stale when changes in one location do not immediately reflect across all nodes. This can be mitigated by implementing automatic data synchronization, ensuring updates are applied in real-time across all systems.
- Regular data audits: Regular data audits and quality checks help to prevent stale data by identifying potential sources of outdated information. By reviewing timestamps, detecting missing values, and analyzing usage logs, you can ensure data quality meets required standards and take preventive measures when needed.
- Structured data governance: Implement a strong data governance policy with clear data ownership. Defining responsibilities ensures accountability and encourages users to maintain data freshness.
Mitigating stale data: how Quadratic plays a crucial role
Quadratic is an AI-powered spreadsheet designed to accelerate the journey from raw data to actionable insights while ensuring data freshness. As modern data analytics grow more complex, Quadratic's advanced capabilities help users to navigate this complexity, maintaining data quality and fostering a data-driven culture. This makes Quadratic one of the best open source spreadsheets to use. Let’s discuss in detail how Quadratic helps to ensure data freshness.
Direct connection to databases and APIs
Quadratic’s direct database connections enable real-time data synchronization, ensuring freshness by instantly updating data across all nodes. Users can make changes to their databases without the need for manual synchronization, reducing the risk of errors and improving efficiency.
By connecting directly to databases and APIs, Quadratic delivers fresh, ready-to-analyze data. It provides native connection to databases like Microsoft SQL server, MySQL, and PostgreSQL.
Built-in AI capabilities
By leveraging its built-in AI capabilities, Quadratic helps users to identify stale data right from their spreadsheet interface. Suppose you’re working with large amounts of data for analysis and you quickly want to identify some stale data that is no longer relevant, you can do so by passing a text prompt in the Quadratic spreadsheet chat. Here’s an example:
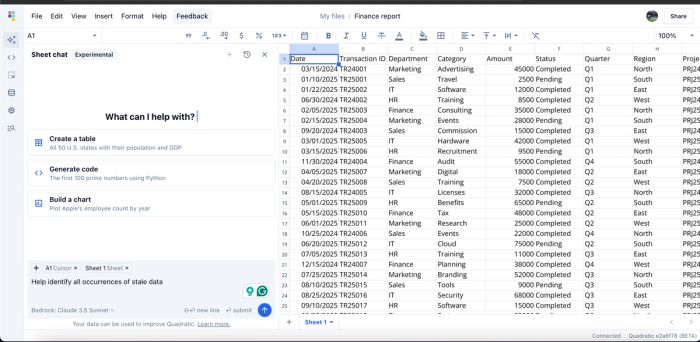
In the above image, I have a large volume of financial data with some instances of stale data. While I could manually identify these occurrences, the process would be time-consuming and prone to errors. Instead, I ask the Quadratic spreadsheet chat to identify all instances of stale data. Here’s the result:
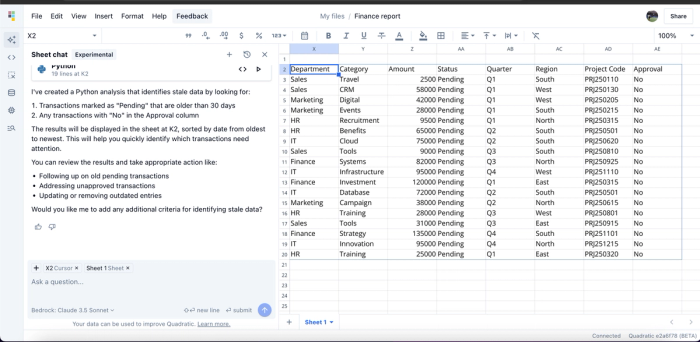
The image above illustrates how data staleness criteria are first evaluated and then applied. The result highlights all data entries with "pending" status for more than 30 days and "No" in the approval column, allowing you to take appropriate action on these outliers. You can specify filtering criteria, such as date entries, to isolate older transactions for further review. This feature allows technical teams and citizen developers to fully leverage AI to maintain data freshness. Learn more about how you can use LLMs for data analysis.
Native support for programming languages
Unlike spreadsheets like Excel and Google Sheets, Quadratic natively supports Python, SQL, and JavaScript. This flexibility makes it suitable as an IDE for data analysis and also allows technical users to analyze and identify stale data. Here’s the code equivalent in Python:
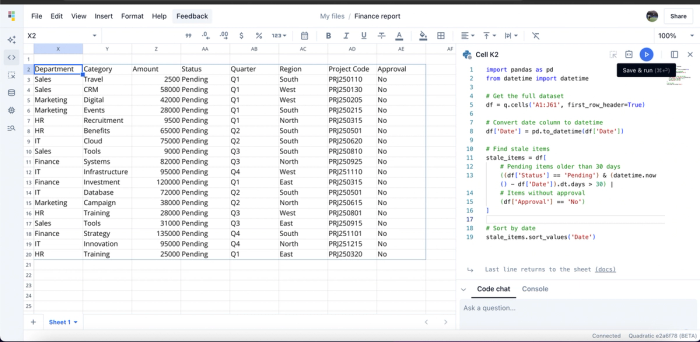
When you click on “Save & run”, it gives the same result.
Conclusion
Stale data hampers decision-making and disrupts a data-driven culture. To gain actionable insights from your data, it’s important to implement strategies that effectively prevent and mitigate its impact.
In this blog post, we explored stale data, its causes, how to identify it, its effects, and strategies for prevention. We also highlighted how Quadratic helps to maintain data freshness through direct database connections, built-in AI capabilities, and native support for modern programming languages. Try it for free today!