
Luke Posey, Product Manager
Mar 26, 2025

Fine-tuning AI models presents many unique challenges that can only be solved through experimentation. Constructing datasets for fine-tuning LLMs is no exception.
Below are tips and strategies for constructing training data to fine-tune your models. We will walk through examples from a real dataset we're using for fine-tuning a model at Quadratic.
We are training a custom model for cell placement, because the large language models by default don't have excellent spatial reasoning. We are fine tuning a model for placement to deliver a superior user experience. Through experimentation and various data strategies we're continually improving the rate at which the AI successfully makes a good placement in the spreadsheet. The following image is illustrative of the type of AI decision that needs to be made. Note the prompt and best possible choices.
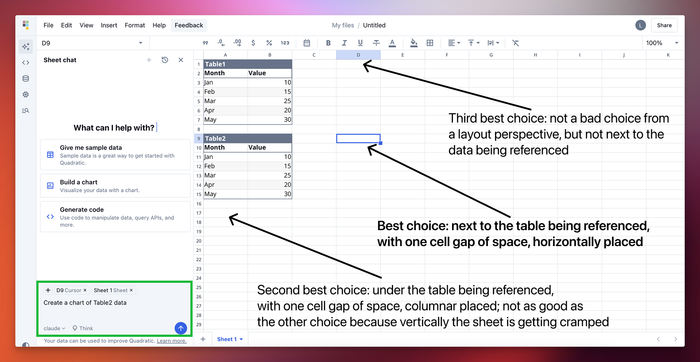
This article is part of a series on fine-tuning tips and best practices. See the most recent article in the series where we discuss AI model selection here.
Dataset construction
With a model in mind, the best place to start is with the construction of a few basic examples. For Quadratic placement, we first created some examples by going into Quadratic and generating data that looks like how sheet bounds are designed in the app. This way, we could create AI training data that reflects how the data is currently communicated in the app.
Our example includes:
- The viewport (what the user is currently looking at in Quadratic)
- All the presently occupied cells in the sheet (and their names, if they have names)
- The code that is in the output (so the AI can figure out how much space it needs to allocate)
{
"from": "human",
"value": "viewport_bounds = \"A1:K50\"\noccupied_cells = [\n{\"table_name\": \"SalesData\", \"bounds\": \"A1:B18\"},\n]\noutput_type = 'Code'\noutput = \"df = q.cells('SalesData')\""
},
{
"from": "gpt",
"value": "A20"
}Once we have a baseline example, the possibilities for going further are broad. For this example, with sheet placement in Quadratic, we’ve sketched out some of the expected thought processes, outlining how we ought to ensure all these thoughts are expressed in training data…
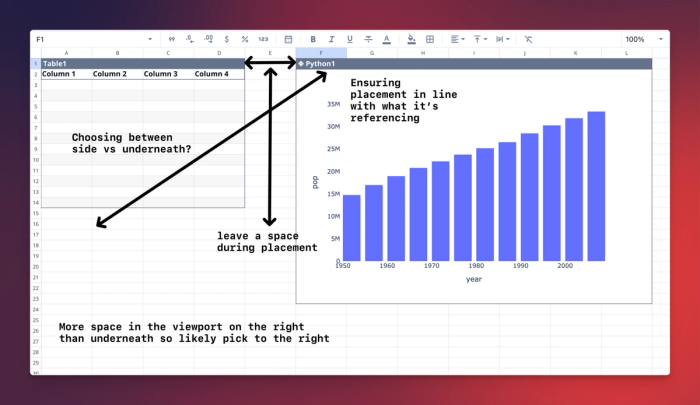
Once we have a handful of examples from every base and broader edge case, we’ll have a good foundation for expanding and introducing more complexity.
Explanation turn
In our example above, we offered examples and expected the AI to pick up on potentially complex patterns. Depending on the model, this may suffice, but in most cases, it helps to explain the thought process behind the example placement.
{
"from": "human",
"value": "viewport_bounds = \"A1:K50\"\noccupied_cells = [\n {\"table_name\": \"SalesData\", \"bounds\": \"A1:B18\"},\n]\noutput_type = 'Code'\noutput = \"df = q.cells('SalesData')\""
},
{
"from": "gpt",
"value": "A20"
},
{
"from": "gpt",
"value": "This example makes sense because the output aligns with the data being referenced and doesn't cause any errors from intersection. It's also placed appropriately, in line with what it references with a single cell gap to the content."
}Generating synthetic data with AI
With our base cases in place, we can generate some synthetic data. These base cases make for a great prompt to start developing that data. Using the most powerful model you have access to, prompt with existing examples and clear instructions on why these examples make sense.
AI-generated data is NOT the magic solution to your data scaling problems. It takes a lot of sophistication to build and prompt models that create consistently reliable data. So, as you generate more and more examples from AI, be more and more diligent about auditing as many examples as possible. The worst thing you can do is generate massive datasets that don’t perform in training and have no idea where to start with finding data quality issues.
Adding negative examples
Another effective strategy is adding negative examples to your datasets. Purposefully add errant examples and make it clear why that’s a NEGATIVE EXAMPLE in the explanation.
{
"from": "human",
"value": "viewport_bounds = \"A1:K50\"\noccupied_cells = [\n {\"table_name\": \"SalesData\", \"bounds\": \"A1:B18\"},\n]\noutput_type = 'Code'\noutput = \"df = q.cells('SalesData')\""
},
{
"from": "gpt",
"value": "A4"
},
{
"from": "gpt",
"value": "NEGATIVE EXAMPLE: this is a bad placement choice because it intersects with content in the sheet, creating an error."
}Accuracy is key
If your training isn’t proving fruitful, the best thing you can do is ensure your examples are high quality. Adding more data doesn’t help if the examples don’t effectively communicate what you’re trying to convey.
When possible, tests and validation should be created to ensure data quality. AI eval can be valuable, but nothing beats a well-trained human evaluator.
Remove dupes
Examples that are very similar (or the same) do more harm than good, adding noise to your dataset. Remove dupes while adding high-quality variety.
Add more examples with more variety
Depending on the size of the model and the scope of the task, you’ll want to add thousands of examples for fine-tuning. However, for simpler tasks like trying to change style, you can often get away with less.
Extraneous information
Depending on your use case, it can make sense to add information unrelated to where the model should be focused. This helps the model understand where it should be focused and not get distracted when irrelevant data is presented in real-world use cases. If the dataset is too uniform, the model may get confused by minor discrepancies in the real world.
Conclusion
Robust, high-quality training datasets can be a difficult but worthwhile endeavor to improve AI performance. Techniques like negative cases, synthetic data, and thorough validation will help you build the best dataset(s) possible, ultimately leading to better model performance.
Want to learn more? This article is part of our AI fine-tuning series. You can read about model selection here.


